แนะนำผู้ที่สนใจ Data Analytics ลองดู video แนะนำคอร์ส Online ของ สถาบัน MIT ครับ
Thursday, October 1, 2015
Wednesday, September 30, 2015
Highly recommended book ML ด้วย Python + Scikitlearn
หนังสือเล่มไหม่เพิ่งคลอดที่ในวงการ Datasci พูดถึงกันมากครับ
สำหรับผู้ที่สนใจ ML ด้วย Python + Scikitlearn เล่มนี้ถือเป็น Bible ได้เลยครับ

http://www.amazon.com/Python-Machine-Learning-Sebastian-Raschka/dp/1783555130/ref=sr_1_2?ie=UTF8&qid=1437754343&sr=8-2&keywords=python+machine+learning+essentials
สำหรับผู้ที่สนใจ ML ด้วย Python + Scikitlearn เล่มนี้ถือเป็น Bible ได้เลยครับ

http://www.amazon.com/Python-Machine-Learning-Sebastian-Raschka/dp/1783555130/ref=sr_1_2?ie=UTF8&qid=1437754343&sr=8-2&keywords=python+machine+learning+essentials
ตัวอย่างการทำ Customer segmentation ด้วย R จาก สถาบัน INSEAD ครับ
ตัวอย่างการทำ Customer segmentation ด้วย R จาก สถาบัน INSEAD ครับ
http://inseaddataanalytics.github.io/INSEADAnalytics/Report_s45.html
http://inseaddataanalytics.github.io/INSEADAnalytics/Report_s45.html
Monday, September 14, 2015
แนะนำ Free-ebook เกี่ยวกับ Data-sci
ขอแนะนำ Free Ebooks 3 เล่ม ดังต่อไปนี้ครับ ซึ่งทั้ง 3 เล่มนี้จะใช้ R programming language ในการสื่อ เป็นหลักครับ ผมคิดว่านัก Data-sci ทุกคนควรมีติดไว้นะครับ ซึ่งผู้แต่งได้อธิบายได้เข้าใจได้ง่าย และเอาไปปฎิบัติใช้จริงได้ครับ
ไว้ว่างๆ จะมาสรุปเนื้อหาแต่ละเล่มให้ครับ
ไว้ว่างๆ จะมาสรุปเนื้อหาแต่ละเล่มให้ครับ
Friday, September 11, 2015
Web Scraping
นอกเหนือความสามารถในด้านการประยุกข์ใช้ machine learning แล้ว ยังมีอีกหนึ่งมีความสามารถสำคัญไม่แพ้กัน นั่นก็คือ การเก็บข้อมูล (Data Collection) นักวิทย์ข้อมุลต้องสามารถดึงข้อมูลได้จากหลายทาง ไม่ว่าจะดึงจาก internal (ข้อมูลจากภายในองค์กร) หรือ external (จากภายนอกองค์กร) เพื่อให้ข้อมุลมีคุณภาพเพื่อที่จะสามารถใช้วิเคราะห์แก้ปัญหาได้ตรงจุดมากขึ้น ตัวอย่างข้างล่างเป็นแหล่งของข้อมูลที่ใช้ในการแก้ปัญหา

- Database ตัวอย่างเช่น Hadoop, MangoDB (NOSQL) , RDBMS
- Social Networking Data API เช่น Facebook , Google , Twitter API
- ข้อมูลที่อยู่บน Website
ในบทความนี้ผมจะมาแนะนำ library ที่ช่วยให้เราเขียน script ดึงข้อมุลจากหน้า website หรือเรียกว่า Web Scraping ที่ชื่อว่า Beautiful Soup ใช้กับ Python ซึ่งตัว library ช่วยให้เราดึงข้อมูลไม่ว่าจะอยู่ส่วนไหนของเว็ปไซต์ได้อย่างง่ายได้ เพียงผู้ใช้แค่ต้องรู้และเข้าใจโครงสร้างของ html
ตัวอย่างกราฟด้านล่าง ผมได้ลองเขียน script ดึงข้อมุล กลุ่มความสามารถที่เป็นที่ต้องการสำหรับสายงาน DataSci ในเมืองไทย จากเวปจัดหางานชื่อดัง ผลปรากฏว่าได้ดังนี้

นี่ก็เป็นตัวอย่างคร่าวๆ ในการนำ library ไปใช้งานดึงข้อมูลจากเว็ปไซต์ครับ
Monday, September 7, 2015
What to do next after applying machine learning?
เคยมั๊ย หลังจากที่ได้สร้าง model และมีความหวังลึกๆว่ามันต้อง perfect แน่ะ แต่แล้วพอได้ลองเทสกับ test data ผลปรากฏว่า performance ไม่ดีเอาเสียเลย (อาจทำเอาเสีย self) ผมเจอบทความๆ นึงที่มีประโยนช์อย่างมากที่สามารถชี้แนะ (advise) ได้ว่า มีหลักการอะไรบ้างที่ต้องนำไปใช้และไปตรวจสอบเพื่อปรับปรุงประสิทธิภาพให้ดียิ่งขึ้น โดยเป็นเนื้อหาที่สอนใน machine learning ของ Andrew Ng จาก Stanford
สามารถอ่านบทความได้ที่ link
สามารถอ่านบทความได้ที่ link
Ensemble method
วันนี้จะมาแนะนำเทคนิคของ advanced machine learning model ที่ช่วยทำให้ประสิทธิภาพการทำนายผล (prediction performance) ดียิ่งขึ้นไปอีก
Ensemble เป็นการสร้างหลายๆ model จาก data ชุดเดียวกัน แล้วนำผลลัพธ์ที่ได้จากหลายๆ model มารวมกัน(combined) อาจะเป็นด้วยวิธีหาค่าเฉลี่ย (averaging) หรือดูจากเสียงข้างมากเป็นหลัก (majority vote)
อัลกอริทึมที่พัฒนาบน concept ของ Ensemble และถูกใช้กันมาก มีดังนี้
1. Bagging Tree คำว่า Bagging ย่อมาจาก Bootstrap Aggregation โดย bagging tree นี้ จะทำการสร้าง หลายๆ subset แบบสุ่มจาก train data แล้วแต่ละชุดจะถูกเรียนรู้ด้วย Tree ผลลัพธ์ที่ได้คือ จะได้ Tree ที่หลากหลาย เนื่องจากเรียนรู้จากชุดข้อมุลแบบสุ่ม (random subset)
ข้อดี
ข้อเสีย
2. Random Forest พูดง่ายคือ Bagging Tree + Random Attribute Subsets ซึ่งตอนสร้าง random subset แทนที่จะรวม attribute ทั้งหมดใน random subset ตัว attribute จะถูก Random ด้วย
ข้อดี
ข้อเสีย เหมือนกับ Bagging Tree
3. Gradient Boosting Tree (GBT) จะแตกต่างกับสอง model ข้างบนตรงที่ การสร้างแต่ละ Tree จะเป็นแบบ Sequence โดย input แต่ละ Tree จะเป็น output จาก Tree ก่อนหน้า โดย concept คือ GBT จะทำการสร้างแต่ละ Tree เพื่อลดค่า error ที่เกิดจาก Tree ก่อนหน้า โดยวิธี Gradient Descend
Ensemble เป็นการสร้างหลายๆ model จาก data ชุดเดียวกัน แล้วนำผลลัพธ์ที่ได้จากหลายๆ model มารวมกัน(combined) อาจะเป็นด้วยวิธีหาค่าเฉลี่ย (averaging) หรือดูจากเสียงข้างมากเป็นหลัก (majority vote)
อัลกอริทึมที่พัฒนาบน concept ของ Ensemble และถูกใช้กันมาก มีดังนี้
1. Bagging Tree คำว่า Bagging ย่อมาจาก Bootstrap Aggregation โดย bagging tree นี้ จะทำการสร้าง หลายๆ subset แบบสุ่มจาก train data แล้วแต่ละชุดจะถูกเรียนรู้ด้วย Tree ผลลัพธ์ที่ได้คือ จะได้ Tree ที่หลากหลาย เนื่องจากเรียนรู้จากชุดข้อมุลแบบสุ่ม (random subset)
ข้อดี
- ค่า variance จะลดลงทันที (Precision เพิ่มขึ้น) เนื่องจากค่าทำนายที่ได้จากแต่ละ Tree จะถูกเฉลี่ย อาจสรุปได้ว่ายิ่งสร้าง Tree มาก ค่า variance ก็ยิ่งลดลง
ข้อเสีย
- ยังคงมีค่า bias อยู่ ซึ่งแก้โดยเพิ่ม depth ของ Tree
2. Random Forest พูดง่ายคือ Bagging Tree + Random Attribute Subsets ซึ่งตอนสร้าง random subset แทนที่จะรวม attribute ทั้งหมดใน random subset ตัว attribute จะถูก Random ด้วย
ข้อดี
- ลดค่า correlation ระหว่าง Tree ได้ เนื่องจาก function Random Attribute Subsets
ข้อเสีย เหมือนกับ Bagging Tree
3. Gradient Boosting Tree (GBT) จะแตกต่างกับสอง model ข้างบนตรงที่ การสร้างแต่ละ Tree จะเป็นแบบ Sequence โดย input แต่ละ Tree จะเป็น output จาก Tree ก่อนหน้า โดย concept คือ GBT จะทำการสร้างแต่ละ Tree เพื่อลดค่า error ที่เกิดจาก Tree ก่อนหน้า โดยวิธี Gradient Descend
Y(actual) = Y(predict) + Error< - (สร้าง Tree เพื่อ predict Error)
แล้วนำผลลัพธ์ที่ได้มารวมกัน ก็จะทำให้ได้ค่าใกล้เคียงกับ Y(actual)
ข้อดี
- bias และ variance ลดลง เนื่องจาก Error ถูกแก้ไข
- แค่ depth ของ tree = 1 ก้เพียงพอที่จะได้ค่า performance ที่ดีขึ้นมาก เมื่อเทียบกับ Bagging Tree และ Random forest ที่ต้องเพิ่ม depth มากขึ้น เพื่อให้ได้ performance ที่ใกล้เคียง
- มีค่า parameter หลายตัวที่ต้อง tune เพื่อให้ได้ค่า performance ที่ดี และเลี่ยงการเกิด over-fitting
Saturday, September 5, 2015
5 สิ่งด้าน Analytic ที่ต้องสร้างสมดุล

เวลานักวิทยาศาสตร์ข้อมูลได้เลือกใช้อัลกอรึทึมในการแก้ปัญหา ต่างก็หวังว่าจะได้ผลลัพธ์ที่น่าอัศจรรย์ แต่บ่อยครั้งไม่เป็นไปอย่างที่คาดหวังไว้เนื่องจากมีหลายข้อจำกัดหรือหลายปัจจัย ดังนั้น มันเป็นเรื่องที่สำคัญมากที่ต้ององค์กรต้องเข้าใจถึงข้อจำกัดเหล่านี้ในขั้นตอนสร้างระบบวิเคราะห์ขั้นสูง โดยเฉพาะอย่างยิ่งปัญหาในโลกธุรกิจริงที่ต้องประสบเจอ คือ
1. Data Complexity หลังจากได้รวบรวมข้อมูลแล้ว สิ่งแรกที่ต้องทำคือ ต้องทำความเข้าใจข้อมูลให้ได้มากที่สุดเท่าที่จะทำได้ ตรวจสอบทุกๆมิติให้รอบด้าน เช่น shape , data type , missing value รวมไปถึงการตรวจว่าข้อมูลที่ได้มาสามารถเชื่อมโยงกันกับสิ่งที่เรากำลังแก้ปัญหาได้หรือไม่
2. Speed เวลาที่ใช้ในการสร้างผลลัพธ์ที่ได้จากระบบ บางธุรกิจต้องการให้ระบบทำการสร้างผลลัพธ์หรือการทำนายทุกๆ 15 นาที แต่ตัวระบบเองใช้เวลาเป็นชั่วโมงในการดำเนินการ ซึ่งก็ไม่ตอบโจทย์ธุรกิจ ความเห็นส่วนตัว อาจแก้โดยหาอัลกอรึทึมที่ใช้เวลาน้อยลงในการประมวลผล หรือ Simple model แต่ก็แลกมาด้วย accuracy ที่ลดลง หรือหา Big data processing solution เช่น Spark มาช่วยเพื่อให้ลดระยะเวลาได้มากขึ้น
3. Analytic Complexity ถูกวัดด้วยความซับซ้อนของตัวอัลกอรึทึมเองและทรัพยากรที่ใช้ในการลงมือทำ บางอุตสาหกรรมนั้นต้องการลดความความซับซ้อนเพื่อให้ที่มาของผลลัพธ์นั้นถูกอธิบาย(Interpretation)ใด้ง่าย เนื่องจากผู้บริหารหรือองค์กรต้องการเข้าใจปัจจัยต่างๆที่ส่งผลต่อผลลัพธ์ในการดำเนินธุรกิจ ซึ่งการลดความซับซ้อนลงนั้นทางนักวิทย์ศาตรย์ข้อมูลก็โดนลดความสามารถในการสร้าง model ที่ดีที่สุดไปได้
4. Accuracy and Precision หลายคนยังคงสับสนกับความหมายคำว่า ถูกต้อง และ แม่นยำ ซึ่งในงานด้านวิเคราะห์ข้อมูลจะพูดถึงสองสิ่งนี้อย่างมาก ถ้าให้อธิบายเข้าใจง่าย ขอแสดงด้วยรูปภาพดังนี้

5. Data Size นักวิทย์ข้อมูลมอง Data size เป็นแบบ จำนวนแถว(observation) กับ จำนวนคอลัมน์(attribute(s) of an observation) ในการทำงาน ยังมีองค์กรอีกมากที่ขาดความเข้าใจที่ว่าข้อมุลยิ่งมาก ย่อมสร้าง output ได้ถูกต้องมากขึ้น แต่อย่างไรก็ตาม จุดที่ต้องพิจารณาเวลาจะใช้ข้อมูลขนาดใหญ่ในการวิเคราะห์นั้นก็คือ Tool เรามีพร้อมหรือไม่ และความสามารถของเรา (Capability)
5 ข้อข้างต้น คือ สิ่งที่ต้องสร้างสมดุลให้ดี และใช้พิจารณาเวลาสร้างโปรเจคด้านงานวิเคราะห์ขั้นสูง
บทแปลจาก link
Wednesday, September 2, 2015
7 ประเภทของ Regression เทคนิค ที่นักวิทยาศาตร์ข้อมูลควรรู้
ผมได้เจอบทความของ blog นึง เขียนเกี่ยวกับ Regression 7 รูปแบบ ที่ควรทราบ ได้สรุปไว้ค่อนข้างหน้าสนใจ ซึ่ง Modern Regression เทคนิคที่ควรรู้และนิยมใช้กันมากในเชิงปฏิบัติ ก็คือ
1. Forward Step-wise regression - จะทำการเลือก Feature ให้โดยอัติโนมัติโดยดูจากค่า measure AIC, BIC ในการเลือก set of feature ซึ่งเหมาะกับ high-dimensional data
2. Ridge Regression - เป็นการ penalize ค่า coefficient เพื่อลดผลกระทบที่เกิดจาก multicollinearity (ตัว predictors , independent vars มีความสัมพันธ์ในทางเดียวกันอย่างมาก) และ high-dimensional data
3. Lasso regression - จะเหมือนกัน Ridge regression แต่ norm ที่ใช้จะเป็น L1 ทำให้ค่า coefficient นั้นมีโอกาสเป็น 0 ได้ ซึ่งนำไปสู่เทคนิคที่เรียกว่า feature selection
ดูบทความเต็มได้ที่ link
1. Forward Step-wise regression - จะทำการเลือก Feature ให้โดยอัติโนมัติโดยดูจากค่า measure AIC, BIC ในการเลือก set of feature ซึ่งเหมาะกับ high-dimensional data
2. Ridge Regression - เป็นการ penalize ค่า coefficient เพื่อลดผลกระทบที่เกิดจาก multicollinearity (ตัว predictors , independent vars มีความสัมพันธ์ในทางเดียวกันอย่างมาก) และ high-dimensional data
3. Lasso regression - จะเหมือนกัน Ridge regression แต่ norm ที่ใช้จะเป็น L1 ทำให้ค่า coefficient นั้นมีโอกาสเป็น 0 ได้ ซึ่งนำไปสู่เทคนิคที่เรียกว่า feature selection
ดูบทความเต็มได้ที่ link
Thursday, August 27, 2015
Tutorial : Linear Regression with Python
Linear Regression หรือ Ordinary Least Square เป็น model ที่ใช้กันมากว่าร้อยปี และนิยมใช้กันอย่างแพร่หลาย ซึ่งถูกจัดอยู่ในกลุ่มที่เรียกว่า Supervised Learning เพื่อใช้ในการ estimate ค่าต่างๆ (quantitative response) จากตัวแปร(Predictors, Independent vars)ที่มีความสัมพันธ์แบบเชิงเส้น โดยแสดงเป็นสมการได้ดังนี้
เราจะใช้ DataSci iterative process ดังนี้
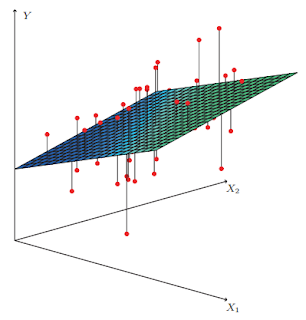 Image source: Introduction to Statistical Learning : Chapter3
Image source: Introduction to Statistical Learning : Chapter3
Y=β+β1∗X
ใน post นี้ ผมจะใช้ Linear Regression โดยใช้ Advertise data (ISL book chapter3) ในการสร้าง Model (สมการเชิงเส้น) เพื่อคาดการ์ณ ยอดขายจากยอดใช้จ่ายสื่อบนวิทยุ โทรทัศน์ และหนังสือพิมพ์ โดยสมการหรือโมเดลที่คาดว่าจะได้คือ
Sales=β+β1∗TV+β2∗Radio+β3∗Newspaper
โดยตัว model ในขณะสร้าง จะพยายามหาค่า β0...βn เพื่อลดค่า Error ให้ได้มากที่สุด หรือกล่าวอีกในนึงคือยอดขายที่คาดการ์ณกับยอดขายจริงต้องใกล้เคียงกันให้มากที่สุด ซึ่งวิธีการที่นิยมที่สุดเรียกว่า Lease Square criterionเราจะใช้ DataSci iterative process ดังนี้
- Understanding and defining problem
- Understanding data via exploratory data analysis (EDA)
- Data Preparation: Data cleansing & Handling missing value
- Build model
- Evaluate model
ติดตามได้ที Click
Monday, August 24, 2015
Awesome MOOC Recommendation for Datascientist
Today i would like to share some great online learning courses for data science which i find them very useful for starting datasci as a career. there are a hundred of data-sci related courses out there on the Internet, offered as degree or certificate. the below are my course recommendation, some of which I already participated and completed.
each course takes about 3-4 months to complete. they offer paid version certificate when the course is complete and minimum score required is passed.
In the next post, I will share a series of basic statistical analysis using R/Python on popular dataset.
| eDX | The Analytics Edge |
| Coursera | Data Science |
| Coursera | Machine Learning |
| Udacity | Data Analyst |
each course takes about 3-4 months to complete. they offer paid version certificate when the course is complete and minimum score required is passed.
In the next post, I will share a series of basic statistical analysis using R/Python on popular dataset.
Wednesday, August 19, 2015
็็How to become a data scientist ?
เชื่อว่ามีหลายคนสนใจและอยากผันตัวเองเป็นนักวิทยาศาสตร์ข้อมูลที่เป็นงานที่ hot ที่สุดในขณะนี้ วันนี้ผมขอมาแชร์ว่า การเป็นนักวิทยาศาสตร์ข้อมุลต้องมี skills ด้านใดบ้าง ผมขอยก Diagram ของนาย Drew Conwey ซึ่งได้สรุป skill ที่จำเป็น แบ่งออกเป็น 3 ส่วนหลักๆ ดังนี้
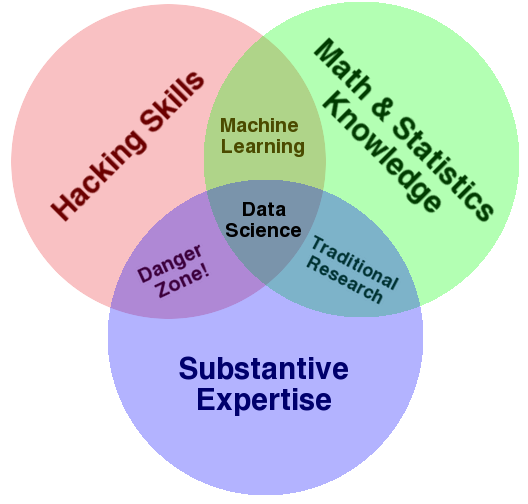
จากรูปจะเห็นได้ชัดว่า Data Science นั้นประกอบด้วย skill set ดังนี้
1. Hacking skills คือ ความสามารถในด้านการเขียนโปรแกรม
2. Math and Statistics คือ มีความรู้ทางด้านสถิติและคณิตศาตร์
3. Domain experts คือ ความรู้และความชำนาญในสายงานของปัญหานั้นๆ
แต่ถ้าใหัชัดคือ Data scientist = Data miner + Business domain expert
แล้วจะเริ่มต้นยังไงละ ?
ผมขอรวบรวมข้อมูลที่เป็นประโยชน์สำหรับการพัฒนา skill ดังนี้ จากประสบการณ์ส่วนตัว
- Learn to love data
การที่จะสร้างความสำเร็จไม่ว่าเรื่องใดๆ ก็ตาม ต้องมี "ใจรัก" เพื่อให้เราก้าวสู่ความสำเร็จ การทำงานด้าน Data science ก็เช่นเดียวกัน บ่อยครั้งนักที่ผู้ศึกษาในช่วงเริ่มต้นต้องถอนตัวไปหรือไม่ก็ท้อแท้ เนื่อจากศาสตร์ด้านนี้ถือว่ายังใหม่มาก learning topic ค่อนข้างกว้าง และยากที่จะเข้าใจในะระยะเวลาอันสั้น ดังนัั้น ลองหาเป้าหมายที่สนใจและอยากลองทำโดยใช้ศาตร์ของ Data science ช่วย ตัวอย่างเช่น บางคนสนใจเรื่องเล่นหุ้น อาจจะลองตั้งเป้าหมายสร้าง model ในการทำนายราคาหุุ้น เขียน Program เชื่อต่อ yahoo finance api สิ่งเหล่านี้เองจะช่วยทำให้เราหลงใหลใน data อย่างไม่รู้ตัวและสนุกกับมัน และจงเชื่อในพลังของ data science ในการเปลี่ยนแปลงโลกให้ดีขึ้นได้ - Programming
ผมแนะนำให้เลือกเรียนภาษา R กับ Python ซึ่งต่างเป็น Opensource ทั้งคู่และได้ถูกใช้อย่างกว้างขวางในด้านวิชาการและภาคธุรกิจ ซึ่งได้มีการพัฒนา library หรือ package มากมายเพื่อใช้ในการทำ Data exploratory analysis หรือ Data modeling
สำหรับคนที่สนใจ R แนะนำให้ดาวโหลด IDE RStudio
สำหรับคนที่สในใจ Python แนะนำตัว Anaconda ซึ่งเป็น Python distribution ที่ได้รวบรวม library ที่จำเป็นต่อการใช้งานด้าน Data science มาไว้รวมกัน - Stats
สถิตินั้นสำคัญแค่ไหน? การที่จะเข้าใจ Data ได้อย่างลึกซึ้งนั้น ความรู้ด้านสถิติจึงจำเป็นอย่างยิ่งต่อการทำความเข้าใจและใช้ในการหาความสัมพันธ์ของข้อมุลและตัวแปรต่างๆ หรือใช้ในการการวิเคราะห์ผลลัพท์ว่ามีนัยสำคัญแค่ไหน ถ้าใครที่พื้นฐานสถิติไม่แน่นผมขอแนะนำหนังสือ Free eBook : OpenIntro Stats ค่อนข้างอธิบายได้ค่อยข้างดี มีรูปประกอบชัดเจน - Machine learning
เป็นการผสมผสานของศาตร์ด้าน Computer science + Stats + Math โดยเรียนรู้จาก Input ที่ป้อนเข้าไป (Training) เพื่อค้นหา pattern หรือ knowledge แล้วสร้างแบบจำลอง model เพื่อใช้ในการแก้ปัญหา
E book แนะนำ An Introduction to statistical learning หรือ
Online learning : Learning from data - Visualization
เป็นการอธิบายด้วยภาพทำให้เราเข้าใจเรื่องซับซ้อนได้เข้าใจง่ายขึ้น ซึ่งจะถูกใช้ส่วนมาก ณ ตอนเวลาทำ Data exploratory analysis และ summary of analytical findings. R และ Python เองต่างก็มี library ให้เลือกใช้หลายตัว แต่ที่ๆ นิยมกันก็คือ ggplot2, matplotlib, seaborn หรือจะลองใช้ Visualization software สำหรับ descriptive analysis เช่น Tableau QlickView - Practice and Practice and Practice
หลังจากได้ศึกษาเรียนรู้แล้ว ให้ลองฝึกฝนกับ data set จริงๆ ซึ่งได้มีหลายเว็ปไซต์ได้รวบรวม data เพื่อให้เราฝึกฝนการวิเคราะห์ครับ ผมขอ share ที่ใช้ประจำดังนี้
UCI
Reddit Dataset
หรือถ้าชื่นชอบความท้าทายแข่งกันกับคนอื่นๆ ลองเข้าร่วมแข่งขันที่ Kaggle ซึ่งจะช่วยให้เรามีประสบการณ์กับการ solving real world problem and learn from other talent peers และทำให้เราเก่งขึ้นไปอีก
Wednesday, August 12, 2015
ตำแหน่ง Data Science ร้อนแรงแค่ไหน

อาชีพที่คนทั่่วโลกพูดถึงกันมากในช่วง 1-2 ปีที่ผ่านมา เป็นสิ่งอื่นไปไม่ได้ นั่นก็คือ Data Scientist หรือนักวิทยาศาตร์ข้อมูล ซึ่งได้รับการยกย่องว่าเป็น The most sexiest job of 21st century จาก Harvard (source)กันเลยทีเดียว และทางบริษัทที่ปรึกษาชั้นนำของโลกอย่าง Mckinseyได้ประเมินว่า เฉพาะในประเทศ US อย่างเดียวจะมีตำแหน่งนี้ขาดแคลนถึง 190,000 ตำแหน่ง และตำแหน่งที่เกี่ยวข้อง โดยเฉพาะ manager level ที่ต้องมีความสามารถและความเข้าใจในการนำข้อมูล Insight ที่ได้จากการวิเคราะห์ของนักวิทยาศาสตร์ข้อมูลนั้น ไปใช้ในการวางแผนหรือปรับปรุงการตัดสินใจที่มีผลต่อการขับเคลื่อนธุรกิจ อาจจะขาดแคลนบุคคลากรถึง 1.5 ล้าน คน ภายในปี 2018
และยิ่งไปกว่านั้น ทาง US government ได้แต่งตั้ง DJ Patil เป็น Chief Data Scientist คนแรก ลองมาฟังวิสัยทัศน์ของนายคนนี้กัน ซึ่งได้พูดไว้ที่งาน Strata+ Hadoop World Conference
จากที่กล่าวมาข้างต้น เห็นได้ชัดว่า สาขาด้านนี้กำลัง Boom มากในต่างประเทศ ไม้เว้นแม้แต่ประเทศเพื่อนบ้านเราอย่าง มาเลเซีย หรือ สิงคโปร์ ได้มีการประกาศหาตำแหน่งกันและแย่งชิงตัวกันให้วุ่น แล้วเมืองไทยละ ??
เท่าที่ได้คุยกับผู้บริหารท่านนึงที่อยู่ในวงการ Big Data ทราบว่า ตอนนี้ในตลาดเมืองไทยเอง กำลังเตรียมตัวบุคลากรกันอยู่ เห็นได้จากมีภาคเอกชนได้ร่วมกับมหาลัยของรัฐบาลได้ร่วมมือกันจัดตั้งศูนย์ Big Data ขึ้น และจัดหลักสูตรให้กับนักศึกษาเพื่อรองรับความต้องการของตลาดในวันข้างหน้าแล้ว
ณ เวลานี้ ถ้าถามว่าบริษัทกลุ่มไหนในเมืองไทยที่พร้อมที่สุดในการลงทุนทำ Big Data Analytic ความคิดเห็นส่วนตัวน่าจะเป็นบริษัทที่มีปริมาณข้อมูลที่ถือครองเยอะที่สุด คือ
- กลุ่มโทรคมนาคม
- กลุ่มธนาคาร
- กลุ่มรีเทลล์ (ค้าปลีก , ค้าส่ง)
- กลุ่ม Logistic
ใครที่ได้อ่านมาถึงจุดนี้และรู้สึกสนใจที่อยากลองเปลี่ยนสายงาน ซึ่งใน post หน้า ผมจะมา share learning path to be data scientist ให้ครับ
Sunday, June 7, 2015
สวัสดีครับ ผมใฝ่ฝันอยากจะเป็น Data Scientist และการเริ่มเขี้ยน Blog นี้คือจุดเริ่มต้นของการตามความฝัน และ ผมจะ share ทุกอย่างที่เกียวกับ Analytics ไม่ว่าจะเป็นเรื่องของ Tutorial หรือ ข่าวสารในวางการนี้ครับ และโดยส่วนตัวผมเชื่อว่า Analytics สามารถเปลี่ยนโลกใบนี้ให้ดีขึ้น แล้วคอยติดตามใน post ต่อไปๆ ครับ
Subscribe to:
Comments (Atom)